Abstract
Although large language models (LLMs) have been largely successful in generating functionally correct programs, conditioning models to produce efficient solutions while ensuring correctness remains a challenge. Further, unreliability in benchmarking code efficiency is a hurdle across varying hardware specifications for popular interpreted languages such as Python. In this paper, we present ECCO, a reproducible benchmark for evaluating program efficiency via two paradigms: natural language (NL) based code generation and history-based code editing. On ECCO, we adapt and thoroughly investigate the three most promising existing LLM-based approaches: in-context learning, iterative refinement with execution or NL feedback, and fine-tuning conditioned on execution and editing history. While most methods degrade functional correctness and moderately increase program efficiency, we find that adding execution information often helps maintain functional correctness, and NL feedback enhances more on efficiency. We release our benchmark to support future work on LLM-based generation of efficient code.
ECCO Benchmark
In ECCO, we evaluate both runtime and memory efficiency of programs across 2 paradigms.
1. History-based code editing
We evaluate the efficiency of programs generated by LLMs using execution and editing history.
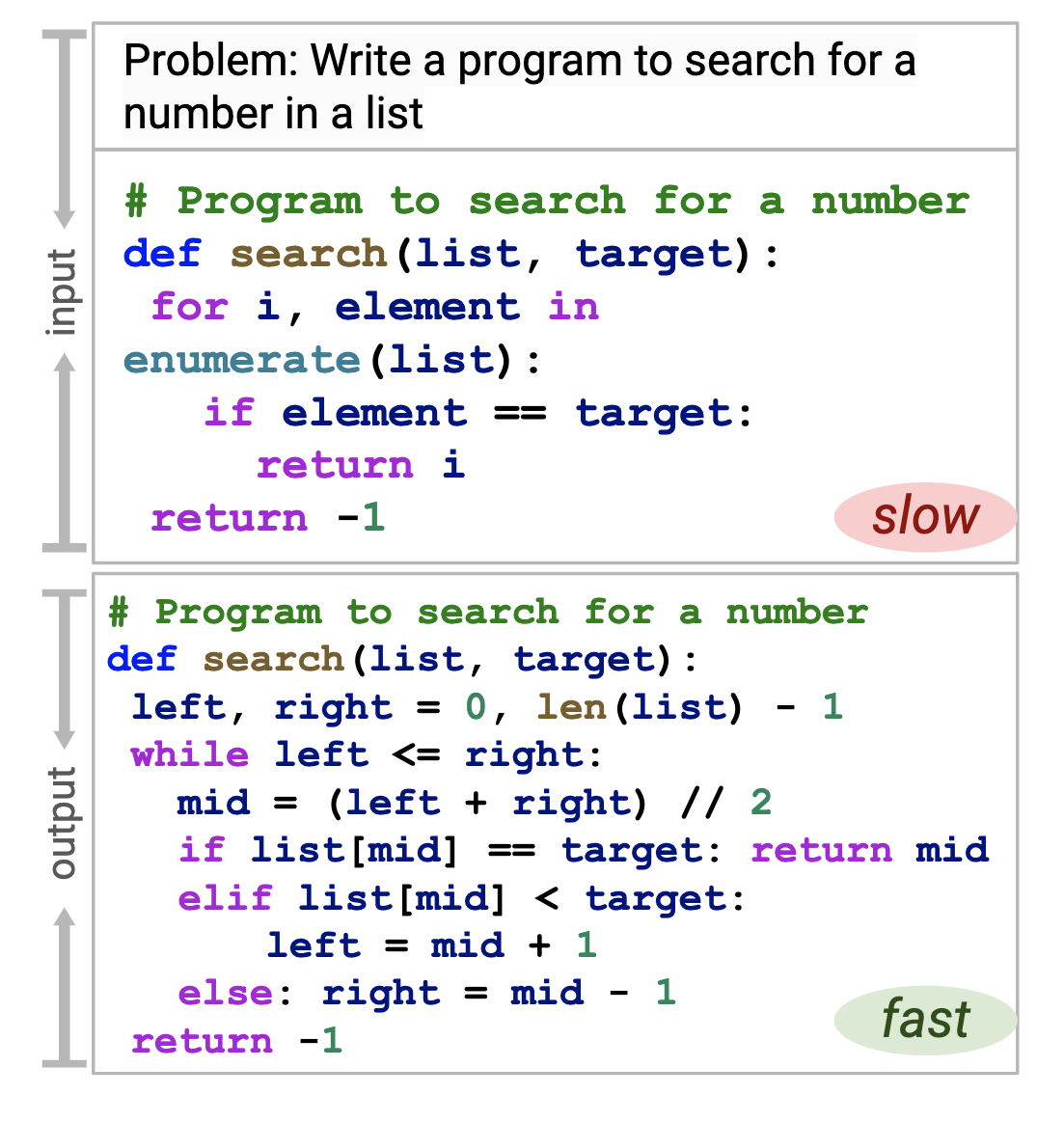
We extend the relative efficiency metrics from PIE (Shypula, 2024) to both memory and runtime:
2. Natural Language (NL) instructed code generation
We evaluate the efficiency of programs generated by large language models (LLMs) using NL prompts. This method explores how well LLMs can interpret and implement efficiency instructions given in natural language.

We introduce relative efficiency metrics which compare generated code against a spectrum of user submitted solutions. This allows us to know each model's efficiency characteristics:
By using these relative metrics, we can assess how our NL-instructed generations compare to human-written code in terms of both speed and memory efficiency.
Evaluation Setup
Measuring the efficiency reliably across different hardware and platforms is challenging especially for interpreted languages. We propose using Judge0 which ensures the same virtual hardware and can measure correctness and efficiency with a simple API call, with support for over 60 programming languages.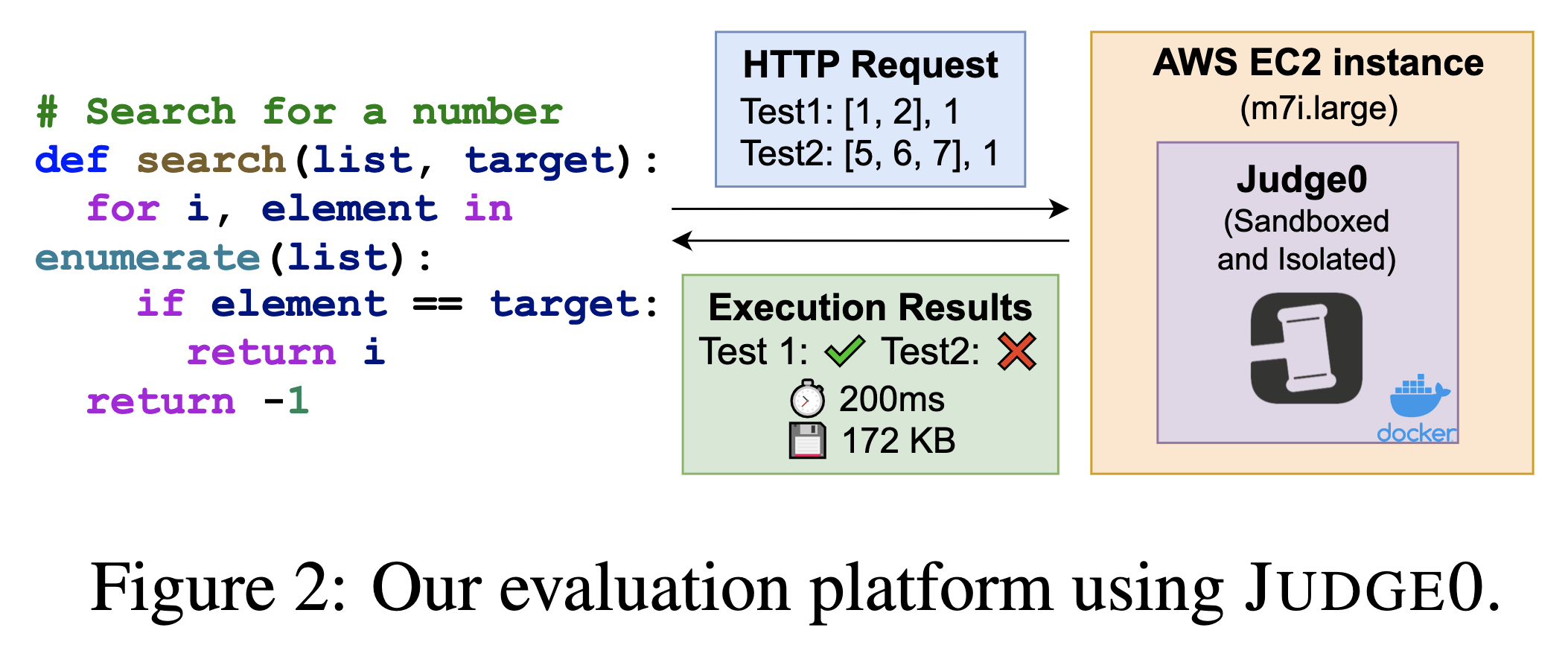
Methods
We explore three most promising classes of approaches:
- In-context learning: Sampling 2 examples from the train set randomly and including them in the prompt
- Iterative refinement
- Self-Refine: Refine code with self-generated Natural Language (NL) feedback from the model
- Execution-Refine: Refine code based on raw execution results (correctness and efficiency) of the previous attempt
- NL+Exec-Refine: Reflect on the raw execution results in Natural Language, and use the reflection to refine the code
- Fine-tuning
- Pair Finetuning: Finetune on pairs of slow & fast programs
- Execution Conditioned Finetuning: Additional context of the raw execution feedback (from exec-refine) for both slow & fast programs
- Trajectory Finetuning: In addition to slow -> fast, we include 3 intermediate user improvements to learn finer grained optimizations
Results and Analysis
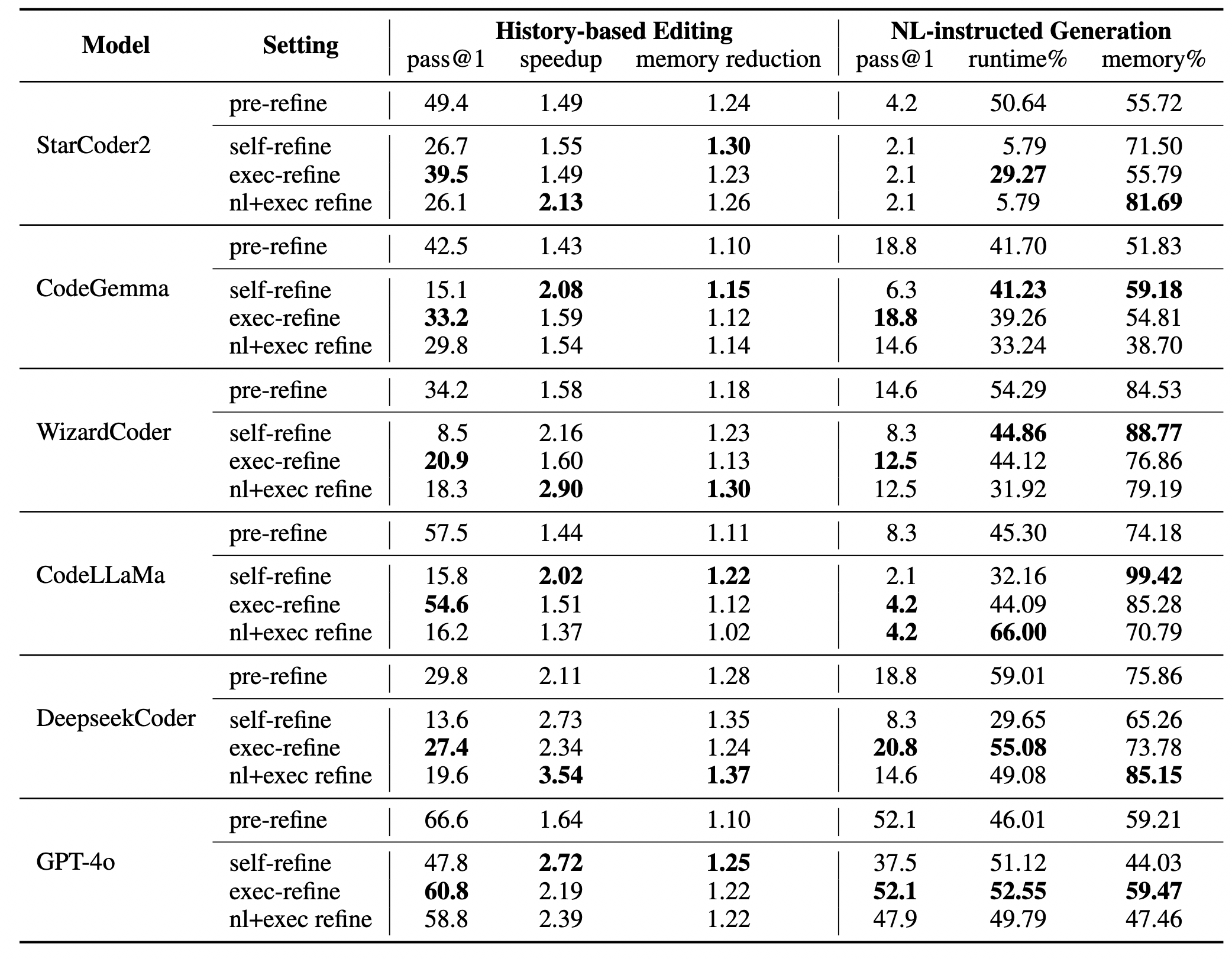
In-Context Learning: Comparing the two paradigms, history-based editing results in a substantially higher pass@1 by referring to a base correct program, compared to NL-instructed generation which lacks a base program to start from.
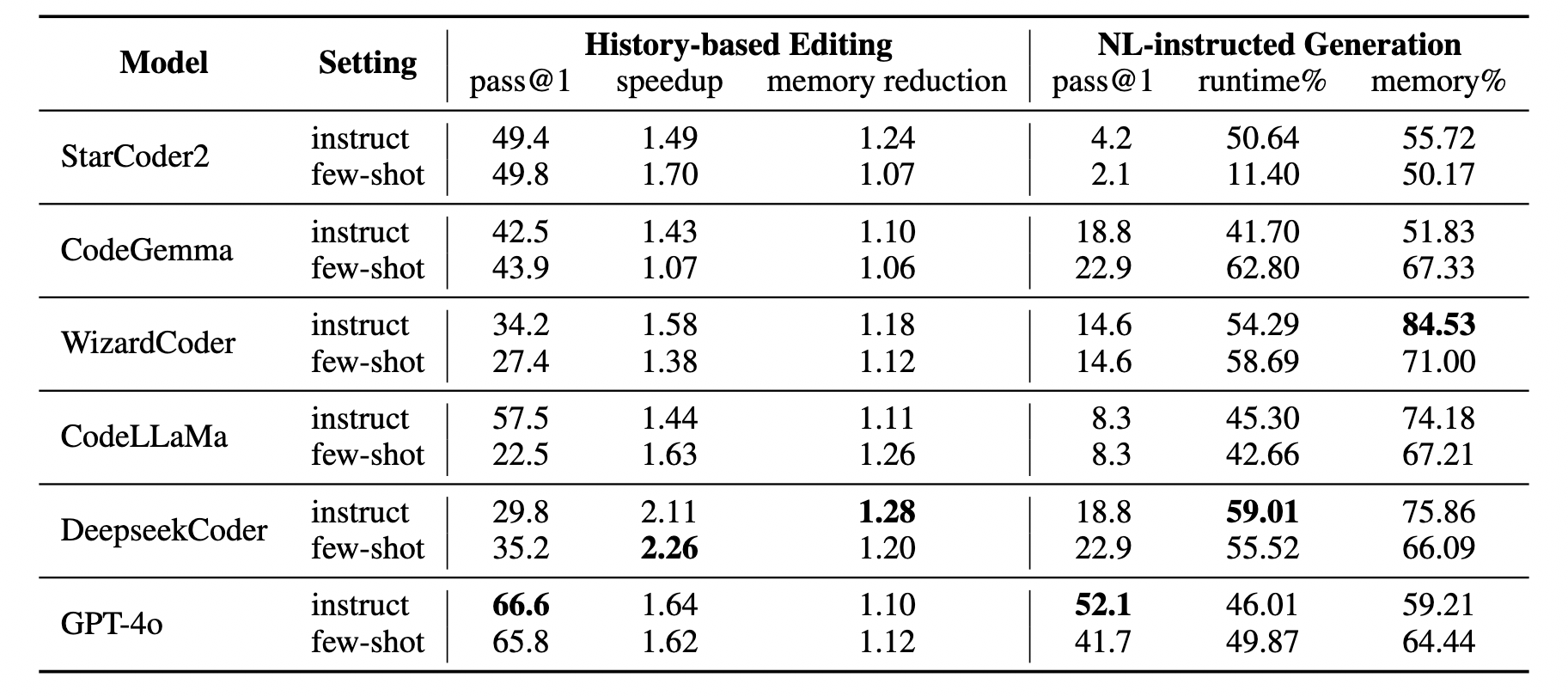
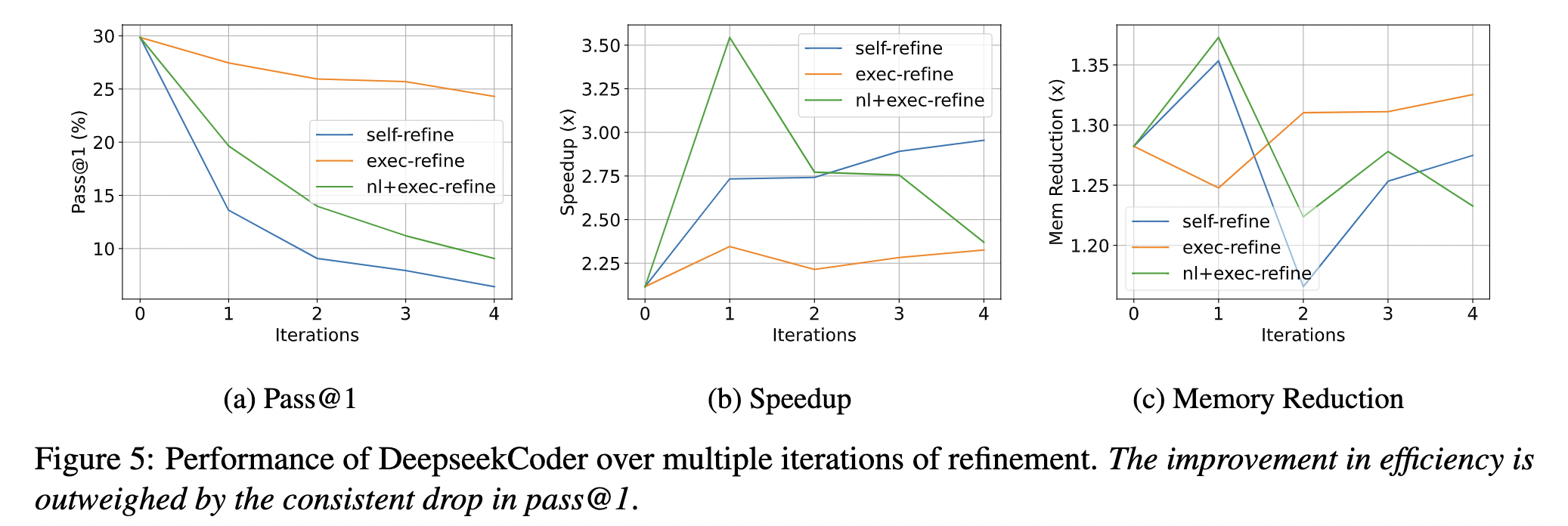
Iterative-Refinement: Methods that involve NL feedback (self-refine and nl+exec refine) achieve the highest speedup across models, whereas raw excution results (exec-refine) can maintain correctness better while optimizing. We conjecture that execution outputs are better representations to inform functional correctness than NL descriptions, while it is easier to convey high-level optimization strategies in NL.
Multiple iterations of iterative-refinement leads to a consistent decrease in pass@1 which highlights the need for more robust methods that emphasize correctness-preserving optimizations.